This is the second post in a two-part series, exploring the world of Serverless and Edge Runtime. In the previous post, we got familiar with serverless - the main focus of this post will be the Edge Runtime, where it can be useful, and what its caveats are.
Edge Location or Edge Runtime
While defining what serverless is was quite straight forward, with edge, we have a little more trouble. When ‘edge’ is mentioned, it can refer to a few, quite different concepts: it can refer to “edge location”, or “edge runtime”, or even “edge functions”. Let’s go through each, and see what exactly they mean.
-
Edge, the Location: the concept of running servers closer to our users. If we take AWS Lambda, we might have one instance deployed in the region us-east-2, meaning that’s where our server spins up and serves users. However, if we have a user from Asia, we can forsee that for him or her, just to reach our serverless function will have latency due to the geographical distance. We can deploy another serverless function in ap-east-1 (running the same exact code as in us-east-2), to serve users from the east, reducing the latency originating from the distance. Lambda@Edge from AWS fits into this category - we are essentially deploying “replicas” of our serverless function, and each user will be served by the instance being geographically closest to them.
-
Edge, the Runtime: unlike serverless functions, where an actual server has to spin up and then serve the request (thus, we bear the cost of the cold start), the edge runtime guarantees an environment where our code can execute immediately on a V8 platform, without the need to start up any new servers. It is a technology that is designed to be integrated into frameworks, not directly into applications - probably most notably, NextJS uses it, but providers like Supabase also built products on top of it. A massive caveat to note is that the Edge Runtime uses Javascript’s V8 engine under the hood, therefore our application must be in Javascript/Typescript as well, and not rely on any component that requires any kind of native runtime (C, C++, Rust, and so on).
-
Edge Functions: these are code blocks, simple functions running on the Edge Runtime. While the Edge Runtime provides the platform for frameworks to use, Edge Functions are our small applications.
Global vs Regional Edge
On paper it might sound better if our servers/functions are as close to the users as possible, since surely, this would reduce the response time for the requests.
Right?
Most of the time, a point to consider here is where our database resides, geographically. Do we have a single Postgres instance running in East US? Since most of the time, our clients (hopefully) do not query the database directly, but go through a backend server, this can get quite important. If this backend is close to the database (in the same region), then the first request between the user and our backend might take a few miliseconds, however, if the endpoint the user hits up on the server does a number of roundtrips to the database (eg. make a query first to see if the user is authorized, then query again to get some data, then query again to fetch something more, and so on), since the backend server is regionally close to the database, these n number of requests will not introduce much latency.
However, if we move our backend away from the database’s region, and place it as close to the user as possible, then the first, initial request between the user and backend will be quicker, but then the server has to make longer roundtrips to the database. This can get out of hand quickly, if our endpoint makes a considerable amount of queries towards the database.
Vercel recommends regional Edge Functions in thise case, which are deployed near to the database dependencies. This means, our Edge Function might not be the geographically closest to the user, but to the database. Alternatively, we could even use globally-distributed databases: Vercel started to offer solutions for these as well, such as Postgres KV, Blob and Edge Config.
By default, Edge Functions will run in every region globally, therefore this regional way of working is something to opt-in, and configure ourselves.
Turso
The company Turso offers an interesting solution to help with this potential issue as well: edge hosted libSQL (SQLite) databases, which are deployed to Fly.io, to 26 locations across the globe. We can strategically choose which locations to deploy to, aiming them to be closest to our Edge Functions to reduce latency. It works by creating a primary instance of our database, which is once created, cannot be moved to a different location. Then, we can spin up replicas of it, which will get synchronized up to the primary database. Read operations will be quick from these replicas, however, write operations would still need to go to the primary database.
Pros and Cons
Having an understanding of what the Edge Runtime and Edge Functions are, we can evaluate some of the pros and cons of them. Starting with the pros:
- No cold starts whatsoever.
- Close proxmity: if we address the previously noted point about not placing our backend service far from our datastores, close proximity can still be achieved.
- Cost: with serverless, we are paying for the compute we’ve used, but with Edge Functions we tend to pay per request. This makes it difficult to compare the cost, but anecdotally, for most usecases Edge Functions tend to be cheaper, on average.
Now to consider some negatives:
- V8 dependency: Javascript/Typescript apps can be executed only: Vercel mentions Node, Supabase mentions deno, as their runtime environment.
- Maturity: the Edge Runetime and Functions are still considered to be bleeding edge technologies.
Migrating our JSON-CSV converter to an Edge Function
Similarly to the previous post, let’s try to get a sense how to actually deploy an Edge Function. The process will feel extremely similar to how our serverless CSV converter was provisioned.
Since our JSON to CSV converter serverless function was written in Go, we cannot port it one-to-one to the Edge Runtime, on Vercel. We’ll have to convert our code either to TypeScript, or Javascript.
We can keep the same project structure, with an “api” folder, however, inside it, we’ll create an index.ts file with the following, example content from Vercel:
export const config = {
runtime: "edge",
};
export default (request: Request) => {
return new Response(`Hello, from ${request.url} I'm now an Edge Function!`);
};The ‘config’ object is necessary to indicate that this is in fact not a serverless function, but an Edge Function - if we were writing a NextJS app, we’d have to use a similar notation as well.
Just like before, the CLI command of vercel deploy can be used to create a staging environment, and vercel --prod to push our API to a production environment.
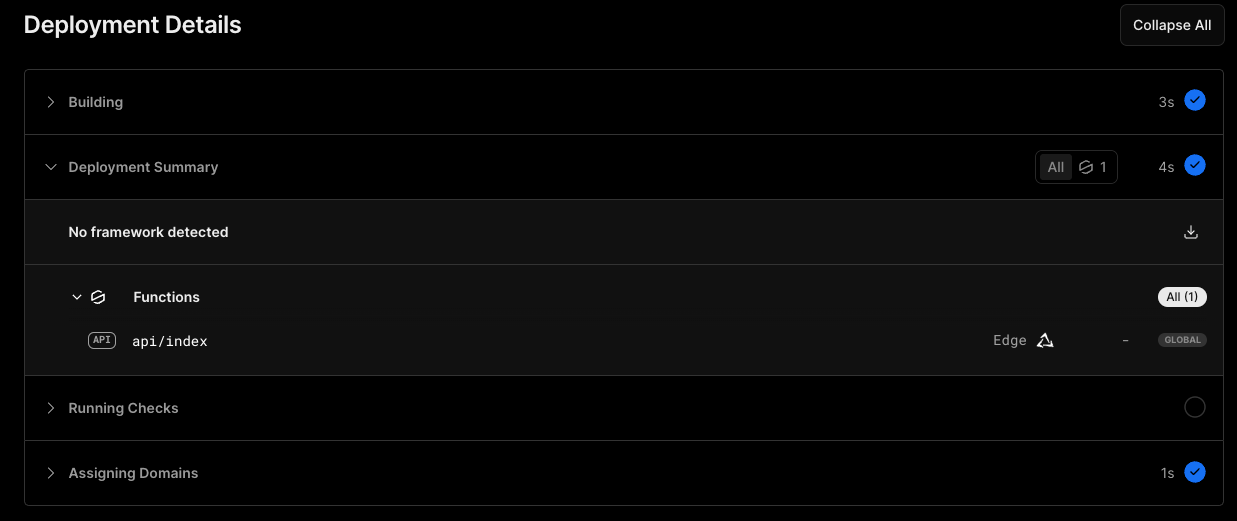
Inspecting the build and deployment on Vercel’s UI, we can confirm that indeed, our code is deployed as an Edge Function, running globally (do you recall from earlier the difference between regional and global? for our CSV converter, since no database connection is necessary, opting to stay on the global deployment model would make sense)
Another point to note here, is the Request and Response objects - they are standard Web API interfaces of the Fetch API.
Let’s now rewrite the Go code to TypeScript:
export const config = {
runtime: "edge",
};
interface EmployeeData {
name: string;
age: number;
jobTitle: string;
badgeNumber: number;
}
export default async (request: Request) => {
if (request.method !== "POST") {
return new Response("Only POST requests are allowed.", { status: 405 });
}
const res = new Response();
res.headers.append("Content-Type", "text/csv");
res.headers.append("Content-Disposition", "attachment; filename=data.csv");
const rows: string[][] = [];
rows.push(["Name", "Age", "Job Title", "Badge Number"]);
let employees: EmployeeData[] = [];
try {
employees = await request.json();
} catch (error) {
return new Response("Could not parse the JSON payload.", { status: 400 });
}
try {
for (const employee of employees) {
const row: string[] = [
employee.name,
employee.age.toString(),
employee.jobTitle,
employee.badgeNumber.toString(),
];
rows.push(row);
}
const csvData = rows.map(row => row.join(",")).join("\n");
return new Response(csvData);
} catch (error) {
return new Response("Could not write CSV data.", { status: 500 });
}
};After deploying it to Vercel, my URL this time is: https://vercel-ts-edge-example.vercel.app/ Just like in the previous post, if you decide to run the following curl, you will be able to convert employees data to a CSV - and this time, no cold starts should be experienced.
curl --location 'https://vercel-ts-edge-example.vercel.app/api' \
--header 'Content-Type: application/json' \
--data '[
{
"name": "John Doe",
"age": 45,
"jobTitle": "Software Developer",
"badgeNumber": 58195
},
{
"name": "Jane Doe",
"age": 32,
"jobTitle": "Software Developer",
"badgeNumber": 58191
}
]'References
- MDN Web Docs (2023). Web APIs. https://developer.mozilla.org/en-US/docs/Web/API
- Theo - t3․gg (2023). That’s It, I’m Done With Serverless*. https://www.youtube.com/watch?v=UPo_Xahee1g
- Vercel (2023). The Edge Runtime. https://edge-runtime.vercel.sh/
- Vercel (2023). Edge Functions Overview. https://vercel.com/docs/concepts/functions/edge-functions
- Vercel (2023). Vercel Edge Functions + Database Latency. https://edge-data-latency.vercel.app/
- Vercel (2022). Vercel Edge Functions can now be regional or global. https://vercel.com/changelog/regional-edge-functions-are-now-available
- Supabase (2023). Edge Functions. https://supabase.com/docs/guides/functions
- Turso (2023). Turso documentation. https://docs.turso.tech/